CodeScribe: Science Hack Day project 2017
Background
On the weekend of October 14th & 15th, 2017, I joined 250 creative and scientific folks at Github HQ for the 8th annual Science Hack Day. It was an extraordinary experience. Not only was this volunteer-organized and -run event exceptionally enjoyable, it was also a masterclass in inclusive event design. Massive thank you to Ariel Waldman and everyone on the Science Hack Day team!
Links:
See the results and findings from this hack
View a copy of the code survey
See the data for yourself

The Birth of CodeScribe
On day one of the event, I addressed the group to propose an idea: a reading comprehension approach to learning code. The idea had come to me only days earlier when I was expressing my frustration at coding education tools. Although there are many freely available online, I’ve never managed to follow through to completion on any of their lessons. “I don’t want to be a coder,” I lamented. “I want to be code literate! Why can’t I read other people’s code and learn that way?” Exploring this thought further, I realized that I had been learning this way. This (along with a bunch googling and helpful CS-savvy friends) is how I learned to build my website, perform statistical analyses, compete in CTFs, and more.
I’m not a coder in my day-to-day activities, but I have developed a level of code literacy that enables me to have meaningful conversations about coding problems and translate between different stakeholders on projects. There are many people like me. People who do not need or want to develop a deep syntactic knowledge of code, but do want literacy: the ability to look at code and understand what it means.
The idea was to combine two needs (that for code literacy and documentation) into one solution. “Duolingo for code,” I pitched it in the pithy this-for-that fashion that has come to define Silicon Valley. Learners would review real code snippets and respond with code comments, collectively crowdsourcing documentation for open source projects. My Science Hack Day cohort responded with enthusiasm.
The first day of the hackathon was primarily used for information gathering, relationship development, and to fail fast on a variety of attempts at bringing this idea to fruition. I connected with educators, students, parents, and professional programmers. My goal was to both better understand the ecosystem of existing resources and to identify patterns in learning styles or barriers to learning. I also talked with the Github team to better understand the options for using their API to make pull requests for comment contributions and to source the code snippets.
Toward the end of the first day, a team had come together. I was joined by Jordan Hart, Erik Danford, and Sanford Barr as core members of our team. We dubbed our project CodeScribe for users’ role as narrators of code’s meaning (with a pleasant double entendre for “co-describe” the process of crowdsourcing documentation). Together, we honed in on some fundamental hypotheses to test to inform our development:
- People can learn to understand code by reading snippets.
- You do not need any prior knowledge of coding languages to learn in this fashion.
- There is a way to automate checking comments.
- People want to learn this way. AND/OR People want this skill.
Development
Through a series of thought experiments as well as a few quick-and-dirty prototypes, we arrived at some early discoveries. We challenged ourselves to perform the tasks we would be asking of our learners, to read and comment foreign code. Our initial learning was regarding hypothesis #3. We found that, beyond creating an automated way of checking quality of comments (or “translations”), we first had to define what a good comment was. We arrived at the conclusion that a good comment communicates the “why” of the code, rather than the “how.” While, I stand by this conclusion, it did present challenges for other aspects of our plan.
My initial vision for CodeScribe had been very much like the language-learning app Duolingo: short snippets to be translated into natural language. We were enthusiastic believing that writing comments would make the mobile app interface easy because we wouldn’t run into the issues around spellcheck for typing code. Our revelation about comments, however, meant that the length of code snippets presented to the user needed to be much longer. Determining the purpose of the code relies on context.

With continuous feedback from other Science Hack Day participants, we felt relatively confident in our fourth hypothesis. At the very least, the concept appealed to people. So, with that, it came time to test my boldest, most controversial hypothesis: that people do not need any prior knowledge of coding languages to develop code literacy through reading code. My compatriots (all of whom had studied, practiced, or even taught computer programming) were unsettled by this idea. My theory was that code was, after all, created to be useful to humans and therefore is arranged and named in a somewhat logical fashion. “For English speakers,” I proposed, “many of the terms should be familiar and may even read naturally.”
To truly test this, however, we would need to try it out with actual people! This became the focus of the rest of our time at Science Hack Day. Our final project resulted in a Google Form. We used a modified program from Jordan’s own lesson plan as the sample code and wrote up four different questions to evaluate understanding. All were multiple choice, and they represented different interaction types we envisioned for the CodeScribe: comment selection, code comparison, and function ordering.
You can find a copy of the Google Form survey here: You can find a copy of the code survey here:
goo.gl/forms/YdcLBmwADQepxLU42
Results
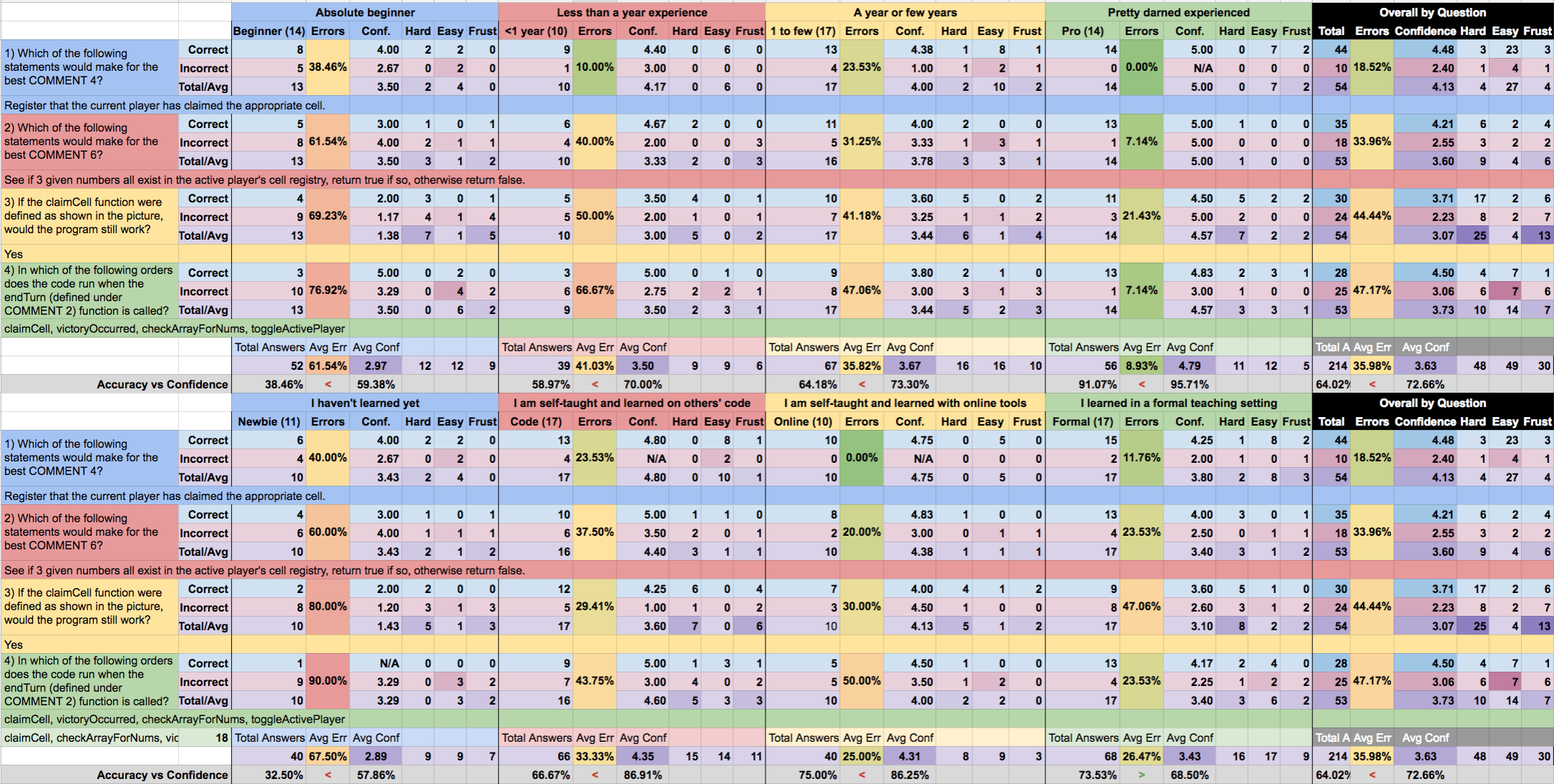
Ultimately, I was terrifically pleased with the results. After three weeks, the survey had accumulated 55 responses from people distributed across all the defined learning methods and experience levels. The findings helped to confirm that those with absolutely no code education could extract some meaning from the code. CodeScribe certainly is not intended to throw people into plain code without guidance, so to me this was a big assurance that I’m headed in the right direction. From the survey, I also learned a lot about lesson design. I look forward to sharing the next CodeScribe prototype with you soon!
Links:
See the results and findings from this hack
View a copy of the code survey
See the data for yourself