CodeScribe: Science Hack Day survey results
Abstract
These findings were gathered for CodeScribe in response to a hypothesis formulated during Science Hack Day. It posits that “[people] do not need any prior knowledge of coding languages to develop code literacy through reading code.” This initial, cursory analysis helps to identify some of the similarities and differences in how different skill level groups respond to the different types of questions. From this, we can gain insights into how easy and intuitive it is for [English-literate] learners to read and understand code without prior experience as well as the types of foundational knowledge required.
Links:
Background on this study and CodeScribe at Science Hack Day
View a copy of the code survey
See the data for yourself
Analysis
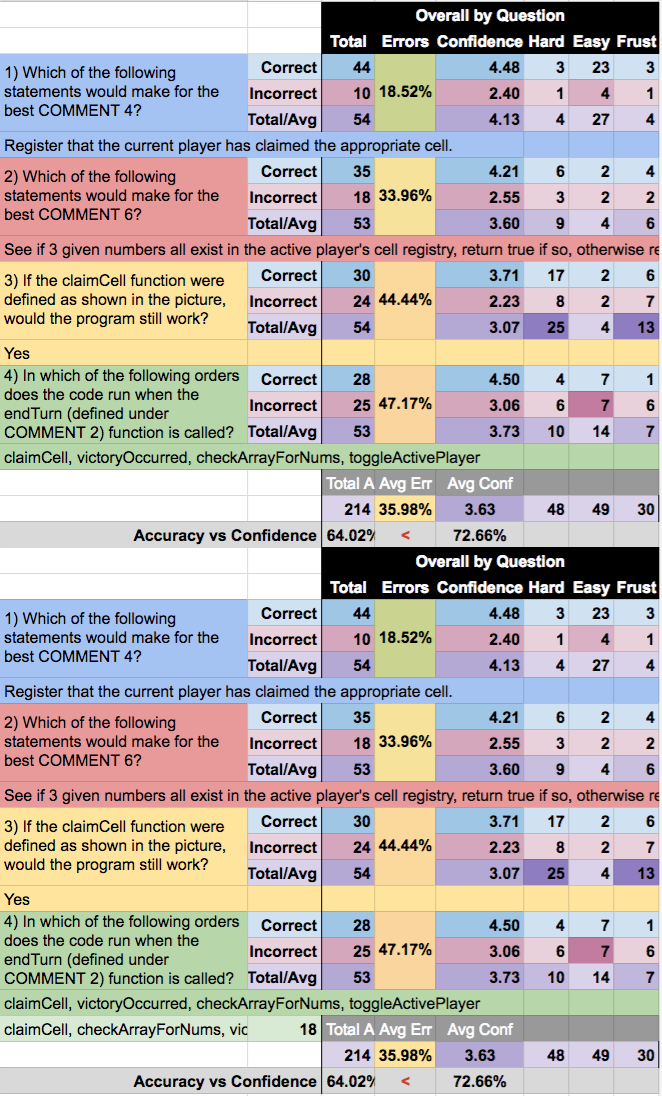
Overall, the “choose the best comment” format questions were easiest for folks to answer correctly. I’m guessing that this is because they read more naturally and (thanks to the limited answer options) could be easier to “guess and check.” Given that one of the fundamental goals of CodeScribe is to help folks develop reading comprehension for code, this is very promising. The comments represent comprehension of the “why” of code above the “how.”
Although there were two questions of this “choose the best comment” type, the error rates varied. I’m understanding this to be due to the somewhat subjective nature of comments. This is to say, the options provided may not have been equally ambiguous. The code excerpts being commented upon may have included different levels of complexity, as well. What is interesting is that for question 1, (both across experience level and across learning method) the incorrect answers were consistent. For question 2, those with less experience and more informal learning tended toward different types of errors than their more experienced, formally-instructed counterparts. This provides helpful insight into the types of disambiguation that should be the subject of future lessons.

Interestingly, question 4 presented a source of confusion that may have come primarily from the question wording. The majority of answers (over 85%!) were distributed between two very similar versions of the answer. This is likely more than confusion between two choices, but in fact may be a semantic distinction in the interpretation of the question. The question asks: “In which of the following orders does the code run when the endTurn (defined under COMMENT 2) function is called?” Here, the ambiguity is in the word “run.” Some answerers treated “running” as being called (which was considered the correct answer here), while others interpreted it as completing.
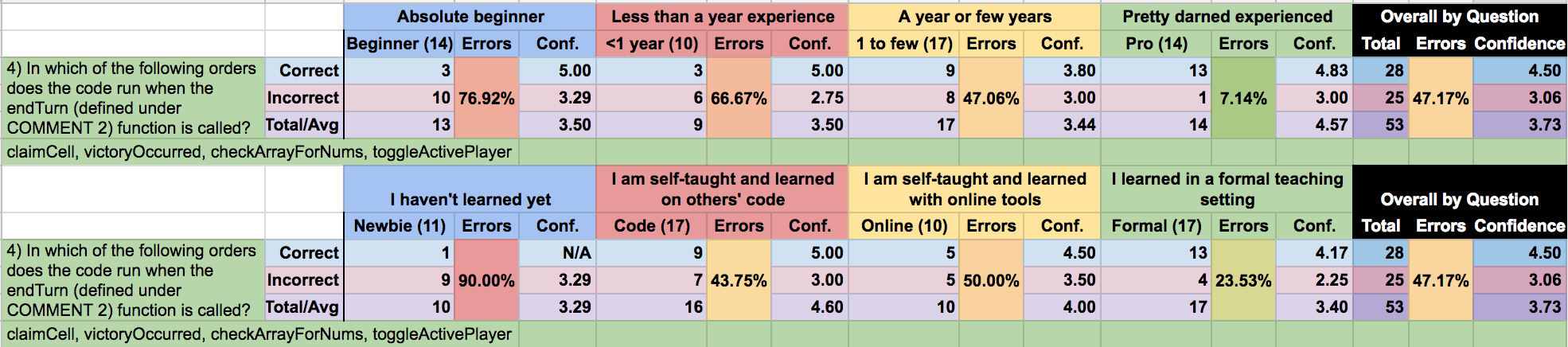
Over 70% of the incorrect answers came in the form of the answer variant which corresponds to the completion interpretation of the word “run.” If we amended the question 4 wording to say “In which of the following orders is the code called when…?” there would almost certainly be a vast improvement in performance. If even half of the respondents who had chosen the variant had clarity from the improved wording, this question would have gone from least- to the second-most-accurately answered in the group. In the future, if presenting similar questions or ordering challenges, I will use less ambiguous language or clarify that run is equivalent to being called.
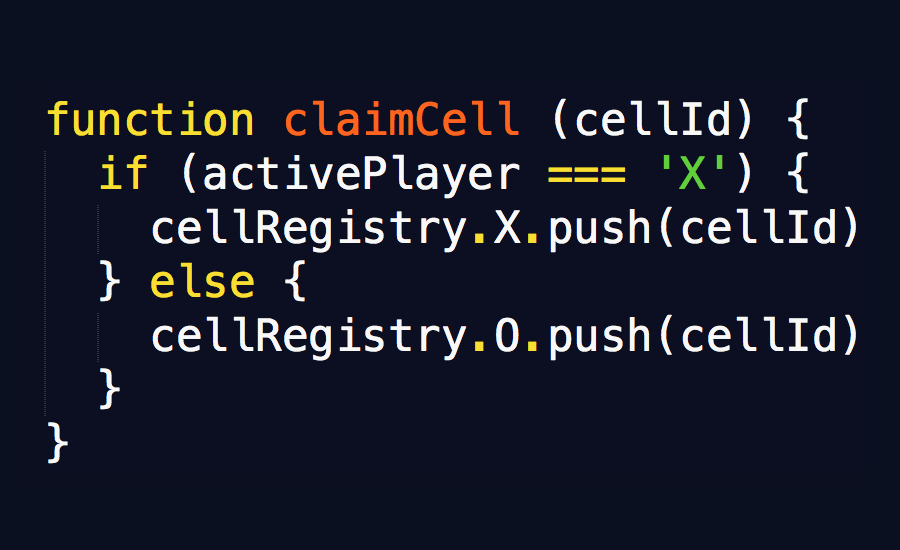
Given the wording confusion in question 4, I think it’s fair to say that—content-wise—question 3 was the most difficult. This was anticipated because the formatting in the provided code was actually quite advanced. Even folks with more advanced skills were more likely to miss it. Across the board, this question type was considered the hardest and most frustrating of the questions, and it may have been a poor choice to include it in this iteration because of the stress it caused. One pretty darned experienced respondent even remarked, “I feel stupid and I’m an expert.”
Because the goal of CodeScribe is to promote reading comprehension for code, questions like this would ideally only be used as teaching moments; they are opportunities to highlight syntax equivalency where it may not be apparent. The lack of feedback in this particular form factor (the Google Form) means that, although helpful for gathering initial insights, it is a far-from-ideal mechanism for teaching. CodeScribe must be interactive and responsive to be effective for learning.
Conclusions
One promising takeaway is that—at least on average—people can sense when they’re getting something wrong. In almost every case, average confidence levels were lower for those who answered incorrectly compared to those who answered correctly. (The main exception to this was for the “Pretty darned experienced” folks on question 3, for which some participants were so confident in their incorrect answers that they outpaced the correct answers in average confidence.)

In the “Accuracy vs Confidence” rows in grey, we see that, despite having less confidence in wrong answers more often than not, the perceived accuracy or confidence was greater than actual accuracy. The one notable exception to this pattern was for the group who learned in a formal teaching setting. On average, these respondents rated their confidence lower than their performed accuracy. I wonder if this is a result of the formal learning environment. As a trend, the difference between confidence and accuracy decreased in relationship to skill level. Both the most experienced and the formal learners had the smallest difference (~5%) but the formal learners’ accuracy was nearly 20% lower as a group than the self-identified experienced coders.
Ultimately, I found these results encouraging. Although those with little to no code education did perform worse, as would be expected, they did better than random guessing (which would have been an average error of 68.75%). I believe with some word changes to question 4, they would actually have performed relatively well. At the end of the day, CodeScribe is intended as a learning tool, not a quizzing tool. As such, the next iteration will be much more interactive and attempt to compare before/after performance.
Links:
Background on this study and CodeScribe at Science Hack Day
View a copy of the code survey
See the data for yourself